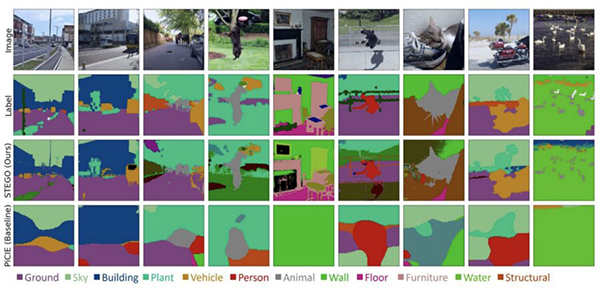
对“CocoStuff27”分割挑战的无监督语义分割预测。STEGO没有使用标签来发现和分割连在一起的对象。与之前的算法不同,STEGO的预测是一致的、详细的,并且不会遗漏关键对象。(图片来源:MIT CSAIL)
给数据贴标签是一件麻烦的事情。它是计算机视觉模型的主要信息来源;没有它,模型将很难识别物体、人和其他重要的图像特征。然而,仅制作一个小时的标记数据往往需要花费人类800小时的时间。随着机器能够更好地感知周围环境并与之互动,我们对世界的高保真理解得到了发展。但机器需要更多帮助。
来自麻省理工学院计算机科学与人工智能实验室(CSAIL)、微软和康奈尔大学的科学家们试图通过创造“STEGO”来解决这个困扰视觉模型的问题,这种算法可以在完全没有任何人为标签的情况下发现和分割像素级的物体。
STEGO所学习的“语义分割”,简单来说是为图像中的每个像素分配一个标签的过程。由于图像中的物体可能会非常杂乱,所以语义分割是当今计算机视觉系统的一项重要技能。而更具挑战性的是,这些物体并不总是适合于文字框;相比于像植被、天空和土豆泥等,算法往往对像人和汽车这样的离散的“东西”有更好的效果。先前的系统可能只是简单地把一只在公园里玩耍的狗这个小场景看作是一只狗,而通过给图像的每一个像素赋予标签的特征,STEGO可以把图像分成几个主要成分:一只狗、天空、草和它的主人。
给世界上的每一个像素都打上标签,尤其是在没有人为反馈的情况下,是一个尤为宏大的工程。今天绝大多数的算法都是从大量的标签数据中获得信息,而这些信息的来源往往需要耗费大量的人力时间,试想一下,为10万张图片的每一个像素打上标签是一件多么令人震惊的事。为了在没有人为引导的情况下发现这些物体,STEGO会在整个数据集中寻找出现的类似物体,然后将这些物体联系在一起,为它学习的所有图像构建一个一致的世界视图。
观察世界
能够“看”的机器对一众如自动驾驶汽车、医疗诊断的预测模型等新兴技术是至关重要的。由于STEGO可以在没有标签的情况下学习,它可以在许多不同的领域进行物体检测,甚至是那些人类尚未完全理解的领域。
“当你在看肿瘤扫描、行星表面或高分辨率的生物图像时,如果没有相关的专业知识,你很难知道你要寻找的是什么。在新兴领域,有时甚至人类专家也不知道正确的对象应该是什么。”麻省理工学院电子工程和计算机科学的博士生Mark Hamilton说,他同样是麻省理工学院CSAIL的研究成员,微软的软件工程师,以及一篇关于STEGO的新论文的主要作者,“在这些情况下,倘若你想设计一种位于科学前沿的方法,你不能指望人类能在机器之前弄清楚它。”
STEGO在一系列视觉领域进行了测试,包括一般图像、驾驶图像和高海拔航空图像。在每个领域中,STEGO都能够识别和分割出与人类判断基本相符的物体。STEGO多样化的基准很大程度归功于COCO-Stuff数据集,该数据集由来自世界各地的各种图像组成,从室内场景到运动的人,再到树木和奶牛。在大多数情况下,曾经最先进的系统能够在低分辨率的情况下捕捉到场景的要点,但很难捕捉到细微的细节,如将一个人认作一个圆球,亦或是将一辆摩托车认为是一个人,它也无法识别出鹅等动物。而在同样的场景中,STEGO的性能比以前的系统高出近一倍,并能够发现诸如动物、建筑、人、家具等概念。
STEGO不仅在COCO-Stuff基准上将之前的系统性能提高了一倍,而且在其他视觉领域也取得了同样的飞跃进展。当将它应用于无人驾驶汽车数据集上时,STEGO也成功地将道路、人和路标分割开来,其分辨率和细粒度比以前的系统要高得多。在来自太空的图像上,该系统甚至能将地球表面的每一平方英尺的图像都分解为道路、植被和建筑物。

(图片来源:Pixabay)
像素间的联系
代表着“基于能量的图优化自我监督转化器”的STEGO建立在DINO算法之上,该算法通过ImageNet数据库中的1400万张图像了解世界。STEGO通过一个学习过程来完善DINO的主要部分,该过程模仿人类将世界的各个部分拼接在一起以产生意义的方式。
例如,你可能会想象两张在公园里散步的狗的图像。尽管它们是不同的狗,有不同的主人,在不同的公园,STEGO依然可以(不依靠人类)分辨出每个场景的对象是如何相互关联的。作者甚至探究了STEGO的内核思想,想知道图像中每个棕色毛茸茸的小东西有何相似之处,以及与草和人等其他共同的对象之间的相似之处。通过将图像中的物体连接起来,STEGO构建了一致的词汇观。
Hamilton表示:“这些类型的算法可以在很大程度上以自动化的方式找到一致的分组,因此我们不必自己去做。理解复杂的视觉数据集(如生物图像)可能需要花费数年的时间,但如果我们能够避免花费1,000小时梳理数据并为其标注,我们就可以找到并发现我们可能错过的新信息。我们希望这将有助于我们以更有经验的方式来理解视觉词。”

通过STEGP算法,科学家试图解决困扰视觉模型的大量标签问题。STEGO可以在完全没有任何人为标签的情况下同时发现和分割像素级的物体。(图片来源:MIT CSAIL)
展望未来
STEGO尽管有了许多改进,但它仍然面临着一些挑战。其一,标签可能是任意的。例如在COCO-Stuff数据集中,它的标签区分了香蕉、鸡翅这样的“食品”和糁、面这样的“食品原料”,但STEGO在此处并没有做区分。再者,STEGO会被一些奇怪的图像所迷惑,比如有一张香蕉放在电话机上的图像,电话机被打上了“食品”,而不是“原料”的标签。
在接下来的工作中,他们计划赋予STEGO更多的灵活性,而不是仅将像素标记为固定数量的类别,因为现实世界中的事物可能同时是多种事物(如“食物”、“植物”和“水果”)。作者希望这将为算法提供不确定性、权重和更抽象的思维空间。
“在制作一个能够理解潜在的复杂数据集的通用工具时,我们希望这种类型的算法可以使从图像中发现物体的这一过程自动化。在很多不同的领域,人为标注的成本过高,亦或人类甚至根本不知道具体的结构,比如在某些生物和天体物理领域。我们希望未来的工作能够应用于非常广泛的数据集。由于你不需要任何人为标签,我们现在开始更加广泛地应用ML(machine learning,机器学习)工具。”Hamilton说。
“STEGO简单、优雅,而且非常有效。我认为无监督分割是图像理解进展的一个基准,也是一个非常困难的问题。牛津大学工程科学系计算机视觉和机器学习教授、视觉几何小组共同负责人Andrea Vedaldi说:“随着transfromer模型的应用,学术界在无监督图像理解方面取得了巨大的进展。这项研究也许为无监督分割的进展提供了最直接和有效的证明。”
Hamilton与麻省理工学院CSAIL博士生Zhoutong Zhang、康奈尔大学助理教授Bharath Hariharan、康奈尔科技大学副教授Noah Snavely和麻省理工学院教授William T.Freeman共同撰写了这篇论文。
作者:Rachel Gordon
